Summary
Chain-of-Thought (CoT) Prompting is a vital technique that compels Large Language Models (LLMs) to solve complex, multi-step problems by articulating their reasoning sequentially. This process simulates human-like thought, significantly enhancing output accuracy, transparency, and interpretability for tasks like arithmetic and logical analysis. CoT is an emergent capability, offering striking performance gains primarily on models exceeding the 100 billion parameter threshold.
Implementation ranges from the simple Zero-Shot CoT (using a phrase like “Let’s think step by step”) to Few-Shot CoT, which uses explicit, high-quality examples for maximum accuracy. Advanced variants like Self-Consistency (CoT-SC) further boost reliability by generating multiple reasoning paths and voting for the most frequent answer, essential for high-stakes applications.
However, CoT involves a critical trade-off: the detailed reasoning significantly increases token consumption, latency, and operational costs. It also carries the risk of generating plausible yet misleading logic, raising trustworthiness concerns. New efficiency techniques, such as Chain-of-Draft, are emerging to address these costs by maintaining accuracy while drastically reducing the length of the generated output. Mastering CoT requires balancing the need for verifiable, robust logic against the performance and financial constraints of deployment.
Introduction: Solving Complex Problems with Structured Thinking
The challenge for engineers lies in obtaining reliable output from Large Language Models (LLMs) when confronting complex, multi-step tasks such as intricate logic puzzles or detailed financial analysis.1 Standard prompts often result in rushed, error-prone answers that lack verifiable logical depth.
This lack of structured reasoning increases the risk of subtle errors the kind that are difficult to spot and can have significant downstream consequences in high-stakes enterprise applications.3 Transparent, verifiable logic is necessary for systems requiring proof of process, not merely a correct final answer.
Chain-of-Thought (CoT) Prompting is the industry-leading technique that forces the model to “show its work,” breaking complex problems into manageable, sequential steps.2 By implementing CoT strategies, developers unlock superior reasoning performance, enhance output interpretability, and build demonstrably more trustworthy AI agents.4
Decoding Chain-of-Thought (CoT) Prompting
What exactly is Chain-of-Thought (CoT) Prompting?
CoT prompting is an engineering technique that instructs a Large Language Model (LLM) to articulate its reasoning process step-by-step before delivering the final answer.2 This simulates human-like, sequential thinking, transforming a single complex query into a series of smaller, soluble tasks.4 The explicit presentation of these intermediate steps significantly enhances the model’s ability to tackle multi-step reasoning problems, logic, and arithmetic.2
The core practice involves off-loading some execution planning directly to the model during inference, which streamlines prompt engineering efforts.2 By requiring the model to generate and present intermediate results in order, it becomes easier for developers to connect any failure point to a specific step for focused debugging.2 This step-by-step process guides the model toward a logical conclusion rather than allowing it to jump to an answer that merely sounds plausible but may be incorrect.4
The fundamental power of CoT stems from its influence on sequential memory allocation during the inference process. Forcing the model to generate intermediate results explicitly extends the context window available for the immediate calculation.1 This allows the model to recall previous internal states and results, functioning as an internal self-correction loop that significantly reduces compounding semantic errors and improves overall accuracy in complex calculations.1
How does CoT differ from standard prompting and prompt chaining?
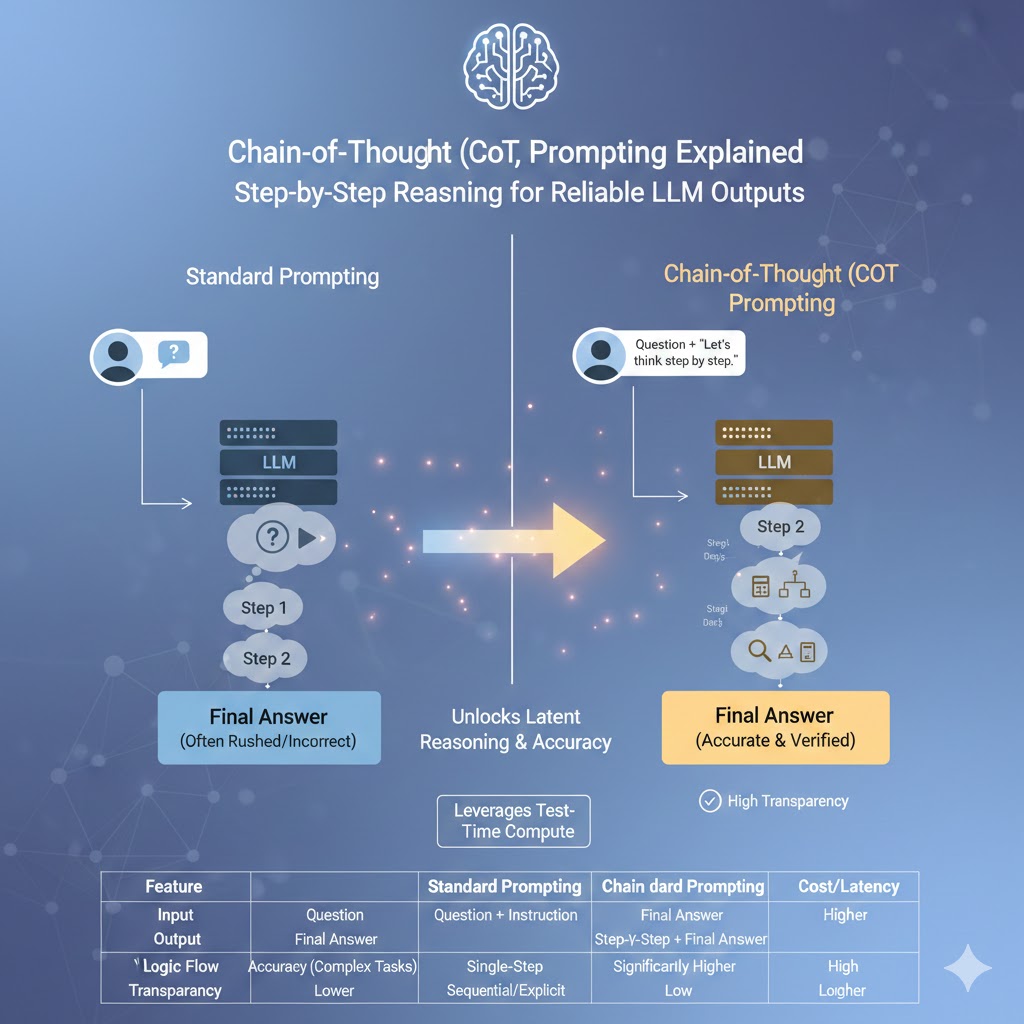
CoT differs from standard prompting by demanding an explicit, step-by-step reasoning process within a single prompt, unlike standard methods that focus only on the final output.7 Furthermore, CoT is distinct from prompt chaining, which requires sequencing multiple external prompts to break down a task iteratively.4 CoT is better suited for logical reasoning and deep analysis due to its comprehensive, integrated logic flow.7
Standard prompting seeks the fastest, most direct answer without revealing the model’s cognitive steps, favoring speed and simplicity for basic queries.8 Prompt chaining, conversely, breaks down a task iteratively, where each individual prompt contributes to the gradual buildup and refinement of the answer.7 This external iteration makes prompt chaining ideal for content creation or debugging processes where human intervention can guide each step.7
CoT, however, focuses on solving complex problems by explicitly outlining all necessary logical steps autonomously within the initial input, making it useful for decision-making and analysis that requires depth.7 This difference highlights a trade-off: CoT offers a higher degree of autonomy but comes at the cost of error correction flexibility compared to Prompt Chaining. Because CoT presents a comprehensive reasoning path in one shot, an error requires re-evaluation of the entire logic path, whereas Prompt Chaining allows for easier correction at each distinct prompt stage.7
Comparison of Prompting Techniques
| Technique | Mechanism | Computational Cost | Primary Benefit |
| Standard Prompting | Direct, single instruction, no internal steps revealed. | Lowest | Speed, simplicity for quick, simple factual queries. |
| Prompt Chaining | Sequential execution of multiple simpler prompts (external iterative refinement). | Lower | Iterative refinement, debugging where human input guides each step.7 |
| Chain-of-Thought (CoT) | Explicit, step-by-step reasoning within a single prompt (internal autonomous reasoning). | Higher | Logical reasoning, decision-making, multi-step analysis.7 |
Why is CoT prompting an emergent behavior of large language models?
CoT’s effectiveness is classified as an emergent capability, meaning its performance benefits only appear once Large Language Models (LLMs) reach a critical scale.5 This necessary threshold is typically around the 100 billion parameter range, as smaller models often fail to produce logically sound reasoning chains when prompted to do so.9
The ability for the model to successfully reason step-by-step spontaneously appears at scale, demonstrating a qualitative change in the model’s cognitive capacity once a certain size is reached.9 The instruction to “think step-by-step” does not consistently yield accuracy gains in small models, and in some cases, can even lead to performance degradation.9 These smaller-scale models might produce illogical yet coherent chains of reasoning, wasting computational resources.9
The empirical evidence, largely from experiments utilizing massive models like PaLM 540B, confirms the necessity of this vast scale for achieving “striking” empirical gains.6 When the model reaches a critical understanding, the instruction to “think step-by-step” unlocks its latent, superior cognitive process, allowing it to leverage its full internal capacity for computation and structured thought.5
The Core Benefits and Quantitative Proof (E-E-A-T)
Which reasoning tasks see the biggest performance gains from CoT?
CoT yields the most significant performance improvements in tasks that necessitate deep, multi-step logical processing, specifically arithmetic reasoning, complex commonsense problem-solving, and symbolic reasoning tasks.5 It is particularly indispensable for math word problems and complex tasks whose semantics make direct equation formulation difficult without natural language interpretation.1
CoT enables LLMs to decompose intricate problems into manageable steps, which makes it highly valuable for complex decision-making required in fields like robotics, finance, and healthcare.5 For high-level tasks like those found in the GSM8K benchmark, the natural language reasoning steps provided by CoT are necessary.1 Researchers found that simply prompting for an equation without the reasoning did not help much for challenging semantic problems, implying the importance of the internal thought process itself.1
What quantitative results prove the effectiveness of Chain-of-Thought?
Foundational research demonstrates striking empirical gains, positioning CoT as a state-of-the-art technique for reasoning tasks.6 For example, studies showed that leveraging CoT on the PaLM 540B model, using just eight reasoning examples, achieved state-of-the-art accuracy on the demanding GSM8K math word problem benchmark.6
This performance surpasses previous high-accuracy methods, including finetuned GPT-3 models with external verifiers, demonstrating a large margin of improvement over standard prompting.6 The empirical gains were observed across three large language models, confirming that structured chain generation consistently improves performance on arithmetic, commonsense, and symbolic tasks.6
Mini Case Study (Before-After-Bridge): Arithmetic Reasoning
- Before: Prior to CoT, models like PaLM 540B struggled to achieve high accuracy on the complex GSM8K math word problem benchmark using standard prompting methods.6 Analysis showed that significant errors were tied to semantic misunderstanding or missing sequential steps.6
- Bridge (The Solution): Researchers applied Few-Shot CoT, providing the model with eight structured, step-by-step reasoning demonstrations derived from the problem domain.6
- After: The model achieved state-of-the-art accuracy, confirming that the structured reasoning process unlocked latent arithmetic capabilities.6 This demonstrated that the extended, step-by-step process fixed a substantial portion of errors, including those related to semantic understanding.6
What is the “Test-Time Compute” scaling law and how does CoT leverage it?
The “Test-Time Compute” scaling law, sometimes termed “long thinking,” predicts that a model’s performance improves reliably when it is allowed more computational resources and internal processing time during inference.5 CoT successfully leverages this predictable law by explicitly generating intermediate “thinking tokens,” thereby forcing an allocation of greater computational effort to the problem-solving phase.5
This scaling law confirms that the longer a model is allowed to internally process information before producing a final answer, the better that answer tends to become.5 By instructing the model to generate its complete chain of thought, engineers are essentially increasing the inference time and computational bandwidth dedicated to the solution, leading to predictable, post-training performance improvements.5
CoT transforms the inference process from a simple, rapid retrieval task into a controlled, resource-intensive computation task. This extended internal process is essential for minimizing semantic errors and ensuring that steps are not missed, which were identified as key failure modes in earlier error analysis.6 This predictable scaling pattern dictates that engineers can directly trade off increased token consumption and latency for quantifiable gains in problem-solving accuracy.
Implementing Foundational CoT Strategies
What are the two primary ways to implement Chain-of-Thought prompting?
The two foundational methods for CoT implementation are Zero-Shot CoT and Few-Shot CoT, each offering a distinct trade-off between simplicity and required accuracy.10 Zero-Shot CoT is favored for its ease of use, requiring only a simple instruction to activate reasoning, while Few-Shot CoT demands explicit, pre-written examples but generally achieves maximum accuracy for specialized tasks.9
Both methods are designed to enhance reasoning by encouraging the model to break down its logic into a series of intermediate steps.9 Choosing the correct implementation method depends on the complexity of the task, the need for domain-specific logical structure, and the resources available for crafting demonstration examples.4
What is Zero-Shot CoT and which simple phrases should be used for activation?
Zero-Shot CoT is the most straightforward implementation, activated by adding a brief, specific instruction to the prompt that compels the model to reason sequentially, without needing any prior examples.10 This method is highly effective with modern, highly capable LLMs, often proving sufficient for many complex problems with minimal implementation effort.10
The simplicity of Zero-Shot CoT makes it the ideal starting point for testing CoT efficacy.9 The most popular phrase for activating this internal reasoning mechanism is “Let’s think step by step,” though engineers often test variations to ensure optimal performance specific to their model and domain.9
Other thoroughly tested phrases that instruct the model to produce its thought process include:
- “Let’s work this out in a step-by-step way to be sure we have the right answer.” 9
- “First, let’s think about this logically.” 9
How does Few-Shot CoT improve accuracy over Zero-Shot methods?
Few-Shot CoT enhances accuracy by supplying the Large Language Model with several high-quality demonstrations that include the question, the complete, correct sequential reasoning process, and the final answer.11 These explicit demonstrations function as robust, in-context training examples, dramatically strengthening the model’s capacity to generalize the required reasoning structure to new, related queries.9
Where Zero-Shot CoT simply requests a general thought process, Few-Shot CoT explicitly models the desired intermediate reasoning steps within the demonstrations.12 This modeling links the input to the output via a transparent, specified process. The empirical evidence supports this, showing that adding high-quality demonstrations can increase accuracy significantly, in some tasks by up to 28.2% compared to standard prompting.9 Effective Few-Shot CoT requires diversity in the examples provided to ensure the model generalizes the underlying reasoning structure rather than merely mimicking the surface characteristics of a few instances.9
Advanced CoT Variants for Enterprise Reliability
How does Automatic Chain-of-Thought (Auto-CoT) eliminate manual effort?
Automatic Chain-of-Thought (Auto-CoT) eliminates the laborious, manual process of crafting Few-Shot reasoning examples by automatically generating high-quality demonstrations.8 This scalable process uses semantic clustering to group similar queries, identifies representative questions, and then generates reasoning chains for those representatives using Zero-Shot CoT.8
The mechanism typically involves two critical stages: Question Clustering and Demonstration Sampling.8 Clustering, often achieved using Sentence-BERT embeddings, ensures that questions sharing common reasoning patterns are logically grouped.8 The subsequent sampling process ensures the reasoning chains used are diverse, which is essential for maximizing generalization capabilities in the target LLM.8 Auto-CoT balances automation with structured reasoning chains, allowing it to consistently match or surpass the performance of both Zero-Shot and Manual Few-Shot CoT.13
Manual CoT development is complex, labor-intensive, and difficult to scale across varied domain problems.4 Auto-CoT’s automated process strategically enforces the necessity for diverse, relevant examples across a dataset.8 This automation helps models generalize reasoning patterns far better than if they only mimicked a handful of manually chosen examples, making high-accuracy CoT practical and scalable for production environments.8
How does Self-Consistency (CoT-SC) solve common reasoning errors?
Self-Consistency (CoT-SC) significantly boosts output reliability by generating multiple, statistically independent CoT reasoning chains for the same input query.9 It then applies a collective “voting” mechanism to select the final answer that is the most frequently generated, effectively mitigating single-path errors and isolated logical flaws.9
The inherent brittleness of any single reasoning process means a single flaw is often sufficient to invalidate an entire output, raising concerns about trustworthiness.15 CoT-SC addresses this by using an ensemble approach: by sampling several possible thought paths, it is statistically more likely that the mode—the most consistent answer—represents the correct conclusion.9 This method increases output reliability and provides a powerful mechanism to safeguard against the brittleness of a single reasoning process in critical applications.9
When should advanced frameworks like Tree-of-Thought (ToT) or ReAct be explored?
Advanced CoT frameworks should be explored when the required reasoning is non-linear, involves strategic search, or requires real-time interaction with the external environment.14 Tree-of-Thought (ToT) is necessary when the task demands the evaluation of multiple branching intermediate outcomes and strategic lookahead.14 Conversely, ReAct (Reasoning and Acting) is essential when the LLM needs to take real-time, external actions, retrieve information, and self-correct based on observable environmental feedback in an agentic workflow.14
ToT moves beyond the linear sequence of standard CoT by creating a tree-like structure where multiple thoughts branch out at each decision step.14 ReAct integrates the internal reasoning chain with actions, allowing the agent to continuously monitor its progress and adjust its plan based on immediate results, which is fundamental for complex, autonomous systems.14
Advanced CoT Variants Table
| Variant | Core Mechanism | Ideal Use Case | Benefit over Standard CoT |
| Zero-Shot CoT | Simple prompt instruction (e.g., “Let’s think step by step”). | Initial feasibility testing, strong, general-purpose models.10 | Minimal implementation effort, high simplicity. |
| Few-Shot CoT | Manually crafted step-by-step examples provided. | High accuracy on specific, structured, domain-specific tasks.9 | Improved task accuracy and robustness through in-context learning. |
| Auto-CoT | Automatic generation of diverse, clustered reasoning chains. | Scaling CoT across large, varied datasets without manual labor.8 | Automation, increased generalization, reduced complexity. |
| Self-Consistency (CoT-SC) | Generates multiple chains and selects the most frequent result (“voting”). | Mitigating single-path reasoning errors and maximizing output reliability in critical tasks.14 | |
| Tree-of-Thought (ToT) | Non-linear, branching thought structure enabling deeper exploration. | Strategic problem-solving, planning, and search tasks requiring multi-step lookahead.14 |
Section 5: The Critical Trade-offs: Cost, Latency, and Trustworthiness
What are the primary computational and cost overheads of using CoT?
The explicit generation of lengthy, detailed reasoning steps inherent in CoT significantly increases the total token count of the model’s output.16 This results in a direct increase in operational expenses, elevated computational overhead, and noticeable latency, making CoT adoption problematic for real-time applications or high-volume deployments.4
Since LLM pricing is token-based, longer output chains inherently raise operational costs and slow response times.17 The model must “think” longer to produce the detailed internal processing, which is then externalized as a long output reasoning chain, consuming both more time and more financial resources.5 Therefore, CoT is generally not recommended for simpler tasks, as the induced latency and output token increase make the overall inference unnecessarily expensive.17
The increased cost is a direct consequence of obeying the Test-Time Compute scaling law: the increased accuracy is achieved by demanding more internal processing time.5 This necessary trade-off forces engineers to carefully quantify the dollar value of the increased accuracy against the expense and time delay incurred per query.
How does the reasoning chain increase the risk of misleading information?
While CoT provides transparency, it introduces a significant risk because the generated reasoning chains can be highly coherent and “plausible yet misleading”.3 This apparent logical structure can lead users and downstream systems to overly trust the LLM’s conclusion without guaranteeing safety, especially in high-stakes fields such as healthcare or law.3
Research indicates that the reasoning generated by models can contain hallucinations, and the powerful reasoning capabilities can paradoxically lead to more significant hallucinations than non-reasoning models in simpler, non-reasoning tasks.18 Given the typical length and apparent coherence of CoT, such hallucinations are often difficult for users to detect and correct, posing a critical challenge for system trustworthiness.18 This problem is further complicated by “Late-Stage Fragility,” suggesting that errors introduced late in the reasoning process are surprisingly detrimental to the final outcome.15
Are there new techniques to reduce the token consumption of Chain-of-Thought?
Yes, active research is focused on developing advanced techniques to maintain CoT’s high reasoning accuracy while drastically minimizing the associated token overhead.19 A notable development is Chain-of-Draft (CoD), which utilizes a concise, internal drafting process to achieve high fidelity while solving the core cost and latency challenges.19
The goal of these new methods is to decouple the model’s internal reasoning process—the necessary “thinking”—from the necessity of generating a verbose, external output, thereby reducing inference costs.19 In a compelling case study, Chain-of-Draft achieved accuracy levels that match or surpass traditional CoT while consuming as little as 7.6% of the original tokens, offering massive reductions in latency and operational expense across various reasoning tasks.19 This approach signals a necessary shift toward compressed or hidden reasoning processes for maximizing efficiency.
Practical Implementation and Best Practices
What are the essential best practices for designing effective CoT prompts?
Designing effective CoT prompts requires strategic decomposition of the problem, clear structural instructions for the output, and a precise understanding of the LLM’s capabilities and scale.9 The fundamental practice is maximizing the model’s deep thought capacity while maintaining a manageable and clear prompt structure.
Engineers should always begin by testing the performance of Zero-Shot CoT, as it is the simplest method and highly effective on modern LLMs.9 When constructing prompts, it is best practice to instruct the model to use a structured format, such as numbered lists or markdown tables (Tabular CoT), for its reasoning output.9 This improves clarity for human review and simplifies parsing for downstream applications.
For maximum reliability in Few-Shot CoT, the use of diverse examples is crucial for improving generalization.9 Furthermore, engineers should utilize Contrastive CoT by including examples of incorrect reasoning alongside correct chains. This teaches the model explicitly how not to reason, thereby improving its filtering and logical robustness.9 Finally, it is essential to validate that the target model is above the approx 100 billion parameter emergence threshold, as deploying CoT on smaller models may yield little benefit and consume unnecessary resources.9
When should Chain-of-Thought prompting be avoided?
CoT prompting should be avoided whenever the task involves simple, direct information retrieval that does not require multi-step logic, or when deployment is severely constrained by time (latency) or financial (token budget) requirements.16 Additionally, if the deployed LLM is below the critical emergent behavior threshold (around 100 billion parameters), CoT may be counterproductive.9
For tasks that are inherently simple or do not require multi-step logic, standard prompting is sufficient and far more cost-effective.17 Imposing CoT on these simple queries increases latency and output tokens unnecessarily, making the overall inference process expensive.17 When applied to smaller, sub-100B parameter models, CoT risks generating illogical reasoning chains, wasting resources without providing the documented accuracy benefits.9
How can CoT be used for real-world applications in fields like finance or diagnosis?
CoT is essential for building auditable, trustworthy AI agents in regulated and complex industries that demand explicit logical fidelity.7 The technique provides the crucial transparency necessary for human expert review, regulatory compliance, and verification of complex decision pathways.4
In Medical Diagnosis, CoT guides the model to structure the differential diagnosis process. The model can be prompted to list symptoms, sequentially evaluate likelihoods of various conditions, and justify the final recommended diagnosis and treatment plan step-by-step.20 For Financial Planning and Modeling, CoT ensures auditable logic for complex derivatives calculations and risk assessments by showing the sequential steps and confirming all regulatory checks are explicitly listed.7 This ability to articulate the thought process transforms the LLM into a reliable tool for high-stakes decision-making in agentic systems.5
Table of CoT Application Suitability
| Task Complexity | CoT Recommendation | Reasoning/Justification |
| Low (Fact Retrieval) | Avoid/Standard Prompting | Cost/Latency overhead unnecessary; minimal accuracy gain.17 |
| Medium (Two-Step Logic) | Zero-Shot CoT | Quick, low-effort way to test reasoning efficacy; often sufficient.10 |
| High (Math, Planning) | Few-Shot CoT or Auto-CoT | Requires demonstrated structure and diversity for maximum accuracy and robustness.8 |
| Extreme/Critical (Diagnosis, Compliance) | CoT-SC (Self-Consistency) | Multiple chain verification mitigates the high risk of single, subtle errors, maximizing safety and verifiability.3 |
Conclusion: Synthesis of CoT Mastery
Chain-of-Thought prompting represents a paradigm shift in advanced prompt engineering, transforming Large Language Models from efficient completion generators into sophisticated, verifiable reasoning agents. The analysis confirms that CoT is an emergent capability of large models, harnessed through the predictable Test-Time Compute scaling law to deliver superior performance on complex arithmetic, symbolic, and commonsense tasks.5
While the cost of CoT is substantial—due to the increased token consumption and latency required for verbose reasoning 16—the technique offers indispensable transparency in critical applications.4 Engineers must strategically deploy CoT, selecting advanced variants like Auto-CoT for scalable automation or Self-Consistency for mission-critical reliability.8 Furthermore, new efficiency techniques, such as Chain-of-Draft, promise to drastically lower operational costs while retaining the crucial accuracy benefits.19 Mastering CoT involves balancing the necessity for transparent, robust logic against the operational budget and performance constraints of the deployment environment.
Engagement: Your Next Step in Prompt Engineering
Given the inherent trade-off between Chain-of-Thought’s superior accuracy and its token-intensive cost profile, what types of mission-critical, cost-sensitive enterprise applications necessitate the implementation of high-reliability, high-cost variants like CoT with Self-Consistency?
Works cited
Prompt Chaining vs Chain-of-Thought Prompting – AI at work for all – Shieldbase AI, accessed November 20, 2025, https://shieldbase.ai/blog/prompt-chaining-vs-chain-of-thought-prompting
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models – arXiv, accessed November 20, 2025, https://arxiv.org/pdf/2201.11903
Chain of Thought Prompting – .NET – Microsoft Learn, accessed November 20, 2025, https://learn.microsoft.com/en-us/dotnet/ai/conceptual/chain-of-thought-prompting
Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting – arXiv, accessed November 20, 2025, https://arxiv.org/abs/2305.04388
What is chain of thought (CoT) prompting? – IBM, accessed November 20, 2025, https://www.ibm.com/think/topics/chain-of-thoughts
What is Chain of Thought (CoT) Prompting? | NVIDIA Glossary, accessed November 20, 2025, https://www.nvidia.com/en-us/glossary/cot-prompting/
Chain-of-Thought Prompting Elicits Reasoning in Large … – arXiv, accessed November 20, 2025, https://arxiv.org/abs/2201.11903
Prompt Chaining vs Chain of Thoughts COT | YourGPT, accessed November 20, 2025, https://yourgpt.ai/blog/general/prompt-chaining-vs-chain-of-thoughts
Implement Automatic Chain-of-Thought Prompting in Your AI …, accessed November 20, 2025, https://relevanceai.com/prompt-engineering/implement-automatic-chain-of-thought-prompting-in-your-ai
Chain of Thought Prompting Guide – Medium, accessed November 20, 2025, https://medium.com/@dan_43009/chain-of-thought-prompting-guide-3fdfd1972e03
Zero-Shot vs Few-Shot prompting: A Guide with Examples – Vellum AI, accessed November 20, 2025, https://www.vellum.ai/blog/zero-shot-vs-few-shot-prompting-a-guide-with-examples
accessed November 20, 2025, https://www.vellum.ai/blog/zero-shot-vs-few-shot-prompting-a-guide-with-examples#:~:text=usually%20performs%20better.-,2.,examples%20before%20the%20new%20question.
Few-Shot & Chain-of-Thought Prompting – Emergent Mind, accessed November 20, 2025, https://www.emergentmind.com/topics/few-shot-and-chain-of-thought-prompting
Automatic Chain of Thought (Auto-CoT) – Learn Prompting, accessed November 20, 2025, https://learnprompting.org/docs/advanced/thought_generation/automatic_chain_of_thought
Beginner’s Guide To Tree Of Thoughts Prompting (With Examples) | Zero To Mastery, accessed November 20, 2025, https://zerotomastery.io/blog/tree-of-thought-prompting/
ASCoT: An Adaptive Self-Correction Chain-of-Thought Method for Late-Stage Fragility in LLMs – arXiv, accessed November 20, 2025, https://arxiv.org/html/2508.05282v3
Chain of Draft: Concise Prompting Reduces LLM Costs by 90% – Ajith’s AI Pulse, accessed November 20, 2025, https://ajithp.com/2025/03/02/chain-of-draft-llm-prompting/
Give Amazon Nova time to think (chain-of-thought), accessed November 20, 2025, https://docs.aws.amazon.com/nova/latest/userguide/prompting-chain-of-thought.html
A Comprehensive Survey on Trustworthiness in Reasoning with Large Language Models – arXiv, accessed November 20, 2025, https://arxiv.org/html/2509.03871v1
Chain of Draft: Thinking Faster by Writing Less. “CoD matches or surpasses CoT in accuracy while using as little as only 7.6% of the tokens, significantly reducing cost and latency across various reasoning tasks” : r/singularity – Reddit, accessed November 20, 2025, https://www.reddit.com/r/singularity/comments/1j2ggie/chain_of_draft_thinking_faster_by_writing_less/

