Summary
The release of Google’s Gemini 3.0 has reignited the debate: have we finally achieved Artificial General Intelligence (AGI)? AGI is defined as a system with human-level performance across all intellectual tasks, characterized by adaptability and abstract reasoning, not just specialized excellence. While current AI, like Gemini 3.0, demonstrates impressive capabilities through massive data scaling, many argue this mimics understanding without possessing it.
Critics, including Yann LeCun, argue current Large Language Model (LLM) architectures are insufficient for AGI. They lack grounding in the real world, often failing at common-sense physical reasoning. LeCun suggests AGI requires integrated world models and explicit planning. Gemini 3.0 addresses these critiques with engineering innovations like “Deep Think,” which enables internal deliberation, and “Structured Task Decomposition” for breaking down complex goals.
Gemini 3.0 represents a significant architectural shift, moving beyond simple prediction to structured planning and multimodal synthesis. Its “Deep Think” mode allocates more compute to complex problems, prioritizing correctness over speed. “Thought Signatures” ensure reliability in long-running agentic workflows by retaining the reasoning chain. The model also boasts a massive context window of over 1 million tokens.
Benchmark results are impressive. In long-horizon planning tests like Vending-Bench 2, Gemini 3.0 significantly outperformed competitors. It also showed substantial improvements in abstract reasoning on tests like ARC-AGI-2. Its multimodal capabilities allow it to interpret complex visual data like charts and UI elements, enabling real-world automation across various fields.
However, despite these advancements, Gemini 3.0 is not true AGI. It achieves AGI-like functions through sophisticated engineering rather than emergent understanding. It lacks a fully grounded world model and requires external guardrails and human supervision. Therefore, it is more accurately classified as “Frontier Agentic AI” or “Artificial General Utility (AGU),” recognizing its immense practical power without implying human-level autonomy or consciousness. The path to true AGI requires deeper architectural integration of sensory learning and physical world models.
I. Introduction: Framing the AGI Question
What is the True Definition of Artificial General Intelligence (AGI)?
Every time a major new foundational model is released, the conversation sparks: Are we finally there? Is this AGI? The difficulty for many professionals is that the rapid pace of technological achievement often outpaces our collective definition of what generalized intelligence truly entails. The core confusion lies in equating hyper-efficient, specialized tools with a true cognitive peer that possesses universal flexibility.
The most stringent standard defines Artificial General Intelligence (AGI) as a hypothetical system capable of successfully performing any intellectual task a human being can.1 Achieving AGI requires more than just high performance; it demands transferable skills, meta-learning, abstract reasoning, and the ability to operate across diverse, complex, and entirely novel environments. This universal applicability, rather than specialized excellence, is the hallmark of true generality.
It is critical to distinguish AGI from Narrow AI, which is what most current systems represent. While a model like Gemini 3.0 may excel at specific tasks—such as coding, scientific hypothesis generation, or complex legal analysis—its high performance on those narrow tasks does not inherently equate to generality.2 AGI requires robust and generalized knowledge application that can seamlessly adapt to domains it was not explicitly trained for, mirroring human flexibility.
Why is Classifying Modern AI as AGI So Difficult?
Modern AI, particularly advanced models like Gemini 3.0, achieves phenomenal utility by expertly mimicking generalized intelligence through massive data scaling and computational power.2 These systems demonstrate abilities that look, sound, and function like human reasoning, making the distinction incredibly complex for the lay observer.
The central challenge is philosophical: determining whether the model possesses genuine understanding, the cognitive “why”or if it merely achieves statistically perfect mimicry the functional “what”.4 While a model can write a flawless proof, the debate remains whether it truly understands the underlying mathematical principles or is simply executing a highly sophisticated prediction routine based on training patterns.
II. The Philosophical Hurdle: Why Current AI Architectures Fall Short of AGI
Why Do Leading AI Researchers Doubt the LLM Path to True AGI?
Influential figures in the AI community, notably Yann LeCun, argue that the current Large Language Model (LLM) architecture is fundamentally insufficient for achieving true AGI.5 He contends that the exclusive focus on scaling these systems is a costly distraction from developing genuine machine understanding.
LeCun has stated publicly that the “shelf life” of current transformer-based architectures is only three to five years, predicting their decline.5 This critique emphasizes that brute-force scaling alone will not yield human-level intelligence, necessitating a deeper architectural shift. These comments frame a high-stakes ideological split regarding the optimal path forward for developing advanced AI systems.5
How Does the ‘Brain in a Vat’ Analogy Explain LLM Limitations?
The limitations of current LLM approaches are often summarized by the philosophical concept of the “Brain in a Vat”.4 This analogy posits that while powerful, models are conceptually isolated because their inherent construction process relies solely on statistical modeling of patterns within massive text corpora to predict linguistic relationships.4
This structural framework results in a lack of grounding, meaning the models fail to connect their linguistic knowledge to the actual physics or causality of the real world. For instance, a model can flawlessly describe the concept of momentum but has never experienced or simulated that force directly.4 This absence of sensory grounding often leads to surprising failures in non-linguistic, common sense physical reasoning tasks.
To bridge this crucial gap, LeCun suggests that AGI architectures must be modeled after human cognition, incorporating access to long-term memory via tools, and dedicating explicit time to both planning and active reasoning.1 This highlights the necessity for integrated world models that understand predictive visual learning and causality.5
What is the Engineering Response to the AGI Philosophical Critique?
The intense focus by Google (Gemini 3.0) and other competitors on developing highly sophisticated agentic workflows and explicit planning architectures is a direct engineering response to the philosophical critique of LLMs. This intensive development suggests an industry-wide recognition that the core predictive architecture alone is insufficient for reliable, autonomous, real-world operation.
The core critique suggests LLMs lack planning, reasoning, and grounding in the world.1 Gemini 3.0 addresses these exact deficiencies by introducing “Deep Think” for internal deliberation, “Structured Task Decomposition” for breaking down complex goals, and highly optimized tool usage.6 The new architectural changes are explicitly designed to functionally simulate the missing cognitive elements that philosophers and researchers have identified as necessary for general intelligence.
III. Gemini 3.0: Architectural Leaps Beyond Prediction
What Defines Gemini 3.0’s Next-Generation Architecture?
Gemini 3.0 represents a clear architectural transition, moving its focus from mere next-token prediction to structured planning and multi-modal synthesis.2 CEO Sundar Pichai championed the model as the “best model in the world for multimodal understanding” and their “most powerful agentic + vibe coding model yet,” signaling a shift toward functional application.2
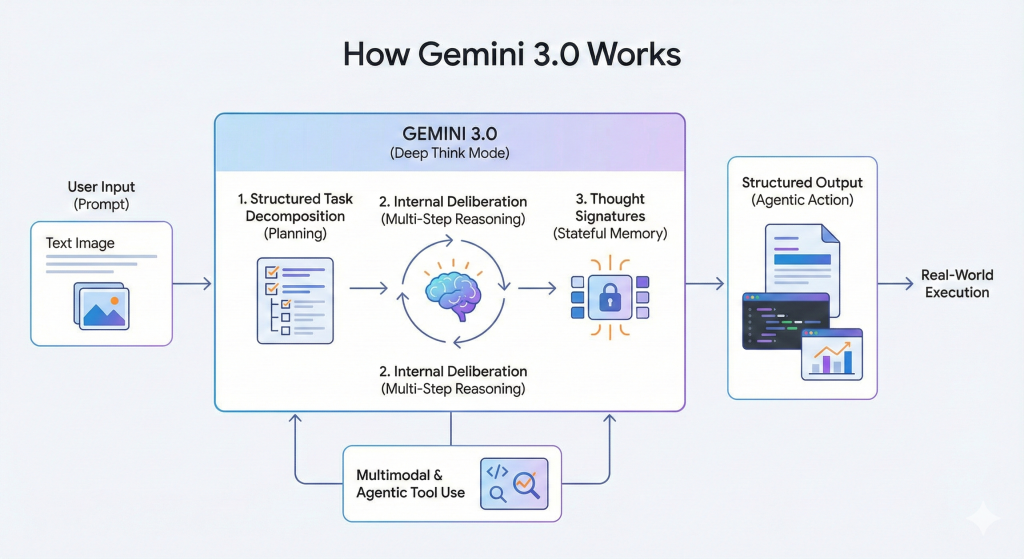
The model’s design prioritizes a seamless synthesis of information across text, images, video, audio, and code, emphasizing state-of-the-art reasoning, vision, spatial understanding, and leading multilingual performance.2 This combination allows it to grasp subtle nuances and dissect complex, multi-layered problems with less explicit prompting than previous generations.2
How Does Gemini 3.0’s “Deep Think” Mode Work?
Deep Think is an adaptive, specialized reasoning configuration within the Gemini 3 family designed to allocate significantly greater computational resources to hard, multi-step, or multimodal problems.7 This process prioritizes internal deliberation and correctness over immediate speed, functioning as a high-compute layer for complex logic and proofs.6
This capability is underpinned by Structured Task Decomposition, where the model first interprets the goal and then explicitly maps out the problem into logical, sequential parts before generating any output.6 This deliberate, architectural change dramatically improves consistency and reduces the tendency toward logical collapse, or reasoning drift, in extended workflows.6
The model achieves Adaptive Effort, similar to how a human focuses harder on a difficult problem, by using Deep Think to spend more computation when tasks become complex.6 Furthermore, because the execution plan is explicit and internal to the model, deviations trigger immediate internal adjustments, allowing Gemini 3 to self-correct and keep long reasoning chains stable and traceable for human review.6
How Do Thought Signatures Ensure Agentic Reliability and Context?
Thought Signatures are specialized, encrypted outputs generated during the model’s internal reasoning phase, specifically before it calls an external tool.8 The core purpose of this innovation is to ensure long-term statefulness and reliability in agentic workflows.
By including these signatures back into the conversation history, the agent can retain the precise, complex train of thought that led to its last action.8 This effectively mitigates the common problem of “reasoning drift” over long, multi-step sessions, ensuring logical consistency which is paramount for high-stakes enterprise tasks.9 For complex agentic tasks requiring sustained focus over many hours, such as the 30+ hours demonstrated by competitive models, this capability becomes a non-negotiable component for enterprise safety and reliability.10
How Does Gemini 3.0 Manage Context Over Massive Data Sets?
Gemini 3 Pro features an extremely large context window, reliably handling over 1 million tokens, which makes it highly effective for specific workflows that require processing vast amounts of data simultaneously.2 This capacity allows developers to input entire codebases, detailed financial reports, or full academic publications into a single prompt.11
The architecture is explicitly engineered for “Large Context Consistency,” ensuring that the model maintains stable logic even across diverse and high-volume multimodal inputs, such as video segments or complex documents.8 While industry best practices often combine moderate context windows with Retrieval-Augmented Generation (RAG) for cost efficiency, the reliable performance of Gemini 3 at the 1M+ token level offers a robust, high-performance alternative for complex payloads.11
To illustrate the technical advancements inherent in this new design, the shift from pure statistical prediction to structured planning is summarized below.
Architectural Comparison: Traditional LLM vs. Gemini 3.0 Deep Think
| Feature | Traditional LLM (Pre-Deep Think) | Gemini 3.0 (Deep Think Mode) |
| Primary Mechanism | Statistical Next-Token Prediction | Explicit, Structured Task Decomposition 6 |
| Reasoning Flow | Single-shot decoding, prone to drift | Multi-stage planning, internal deliberation, self-correction 6 |
| Compute Strategy | Fixed allocation (Low latency focus) | Adaptive/Higher computation (Depth focus) 6 |
| Tool Use Optimization | Function Calling (Add-on) | Integrated Reasoning Loop (Core component) 7 |
| State Management | Context Window only | Context + Stateful Thought Signatures 8 |
IV. Evaluating Gemini 3.0 Against AGI Criteria: Benchmarks and Performance
What Do Gemini 3.0’s Long-Horizon Planning Benchmarks Reveal?
The performance of Gemini 3.0 on long-horizon planning tasks provides strong evidence of its capabilities for complex autonomy. The Vending-Bench 2 analysis, for example, simulates managing a vending machine business over a full year, testing strategic planning, coherent decision-making, and consistent tool usage across an extended temporal dimension.13
In this benchmark, Gemini 3 Pro achieved a mean net worth of $5,478.16, representing an overwhelming 272% better performance than its nearest competitor, GPT-5.1.13 This suggests the model possesses superior strategic foresight and stability over lengthy operational periods, a crucial capability for any practical autonomous agent and a major indicator of AGI-like strategic reasoning.
How Does Abstract Reasoning Performance Compare to Previous Generations?
Gemini 3.0 exhibits profound improvements in abstract visual and non-verbal problem solving, as measured by tests like ARC-AGI-2 and the Humanity’s Last Exam (HLE).13 The ARC-AGI-2 benchmark is particularly important because it assesses generalized problem-solving that cannot rely on pre-trained linguistic patterns.
Gemini 3 Deep Think achieved 45.1% on ARC-AGI-2, a massive jump from Gemini 2.5 Pro’s 4.9% and nearly doubling GPT-5.1’s score of 17.6%.13 Furthermore, the model achieved 41.0% on HLE, a test requiring extended contemplation, which is an 11% increase over GPT-5.1.13 These significant improvements in non-verbal cognition suggest a core architectural change that enables closer steps toward genuine generalized problem-solving capabilities.13
How Does Multimodal Reasoning Improve Real-World Problem Solving?
Gemini 3.0 pushes the frontier of integrated multimodality, combining advanced reasoning with vision, spatial understanding, and high-performance multilingual processing.2 This synthesis allows it to analyze complex input formats that reflect real-world data environments.
The model’s critical capability is interface comprehension, which allows it to reliably interpret visual structures such as logs, tables, charts, UI elements, and complex dashboards.3 This functional breakthrough unlocks true automation in organizational contexts where work happens across screens and visual structures, not just in plain text.6
This ability has direct, high-value utility in diverse fields. For instance, in healthcare, the model can analyze X-rays and MRI scans to assist in rapid diagnostics.3 In scientific research, it can explain patterns, anomalies, and confidence levels within visual data graphs, such as fridge sensor data, which is valuable for predictive maintenance and complex scientific applications.15
Gemini 3.0 Pro Key Reasoning and Agentic Benchmarks
| Benchmark Test | Gemini 3 Pro Score | Deep Think Score | Implication for General Intelligence |
| Vending-Bench 2 (Mean Net Worth) | $5,478.16 | N/A | Superior long-term strategic coherence (272% higher than GPT-5.1) 13 |
| ARC-AGI-2 (Abstract Reasoning) | 31.1% | 45.1% | Significant core non-verbal problem solving leap (Nearly doubles GPT-5.1) 13 |
| Humanity’s Last Exam (HLE) | 37.5% | 41.0% | Unprecedented depth in complex, extended contemplation 13 |
| SWE-Bench Verified (Bug Fixing) | 76.2% | N/A | High-level practical engineering and error rectification 10 |
What Nuance Does the Benchmarking Data Reveal about Agent Profiles?
The benchmarking results highlight that even among highly advanced Frontier AIs, general utility is expressed differently based on architectural optimization. While Gemini 3.0 exhibits dominance in strategic planning (Vending-Bench 2) and novel algorithm creation (LiveCodeBench), it holds a slight lag in practical bug fixing compared to competitors.10
For instance, Claude Sonnet 4.5 maintained a narrow lead in real-world bug fixing at 77.2% compared to Gemini 3’s 76.2% on SWE-Bench Verified.10 This difference indicates that while Claude is highly optimized for deep, persistent analysis of existing environments and debugging, Gemini 3.0’s Deep Think architecture is optimized for novel strategic creation and rapid, integrated multi-domain problem-solving. These distinct strengths show that the race toward generalized intelligence involves various specialized pathways.
V. Practical Agentic Capabilities and Ecosystem
What is the Google Antigravity Platform and How Does it Use Gemini 3.0?
Google Antigravity is an agentic development platform designed to evolve the traditional Integrated Development Environment (IDE) into an agent-centric workspace.16 This architecture presupposes that the AI is not just a tool for writing code but an autonomous actor capable of planning, executing, validating, and iterating on complex engineering objectives.17
The core of the platform is the Agent Manager, a Mission Control dashboard designed for high-level orchestration.17 This manager allows developers to define broad, high-level objectives, such as “Refactor the authentication module” or “Generate a test suite for the billing API,” and then monitor multiple agents working asynchronously.16
This environment fundamentally shifts the human role from “prompt engineering” to that of an “architect” or “manager,” overseeing a workforce of digital agents.6 The human developer retains value by reviewing the model’s high-level assumptions, checking the reasoning logs, and supervising complex, multi-step workflows.6
How Does Agent Awareness Streamline Development Workflows?
Within the Antigravity platform, the Editor view is augmented with “Agent Awareness,” seamlessly integrating the model into the synchronous coding process.17 This includes features like “vibe coding” and inline instruction, where users can highlight sections of code and quickly instruct the agent to “Make this more efficient” or “Add comments explaining this logic”.17
To ensure automation reliability, Gemini 3.0 features an improved JSON Mode that provides structured, reliable output for function calling and tool execution.15 This structured data output is vital for automating subsequent steps in a programmatic workflow, enabling the model to move beyond simple text generation to true, reliable programmatic execution.3
What Are the Real-World Business Impacts of Gemini 3.0’s Capabilities?
The economic value of Gemini 3.0’s integrated planning and multimodal reasoning is evident in real-world applications. A case study involving Presentations.AI demonstrated the model’s ability to analyze complex company information, extract key strategic moves, and generate executive-level content.3
The result was the creation of actionable business intelligence in just 90 seconds, a task that previously required human analysts six hours to compile.3 This highlights how the model’s ability to reason across text, visual data (charts, dashboards), and strategic context provides massive productivity gains for enterprises.3
Enterprises are rapidly leveraging Gemini 3.0 for advanced functions, moving beyond simple task automation.3 Examples include complex long-running tasks such as financial planning, contract evaluation, proactive supply chain adjustments, and the rapid prototyping of full front-end interfaces from minimal prompts.3
Does General Utility Equate to General Intelligence?
Google’s extensive development of ecosystem platforms like Antigravity and granular developer controls, such as the thinking_level parameter and adjustable media_resolution, signals a critical strategy.8 They are actively productizing components that mimic AGI, such as sophisticated planning, stateful simulation, and contextual memory, into a highly marketable layer.3 This functional capability should be correctly termed Artificial General Utility (AGU).
If Gemini 3.0 were truly AGI, it would not necessitate a human developer setting an explicit thinking_level or reviewing detailed reasoning logs to validate assumptions.6 The persistent need for external guardrails, safety filtering, and human supervision as required by frameworks like the Frontier Safety Framework confirms that the model remains a powerful instrument.9 It is a controllable tool requiring external alignment and governance, not an autonomous, generalized intellect.
VI. The Final Verdict: Frontier AI vs. True AGI
Is Gemini 3.0 A True Artificial General Intelligence (AGI)?
Based on the strict and foundational definitions established by cognitive science and leading AI researchers, Google Gemini 3.0 is definitively not a true Artificial General Intelligence (AGI). While its advanced architecture simulates crucial AGI requirements such as long-horizon planning, abstract non-verbal problem-solving, and self-correction it achieves these functions through highly sophisticated engineering rather than emergent, generalized understanding.
The key distinction remains unresolved: Gemini 3.0 has largely conquered the challenges of linguistic and strategic coherence, demonstrating unprecedented agentic power.13 However, it has not architecturally solved the philosophical constraints inherent to the LLM path, specifically the requirement for a fully grounded, emergent world model that understands causality and physics outside of statistical pattern prediction.4
What is the Most Accurate Classification for Gemini 3.0?
The most precise classification for Google Gemini 3.0 is Frontier Agentic AI or, more practically, Artificial General Utility (AGU). This classification accurately recognizes its unparalleled ability to act as a reliable, strategic, and self-correcting agent across nearly every professional and technical domain.3
The model functions as a generalized, high-value assistant that moves beyond simple text generation to complex orchestration. However, by classifying it as AGU, we maintain the necessary technical and ethical distinction from AGI, which implies autonomy, self-awareness, and emergent, human-level consciousness and understanding.
What Are the Next Steps for AI Models to Achieve True AGI?
The trajectory toward AGI requires more than just optimizing planning at the inference layer, which is what Deep Think currently achieves. The next significant step must involve architecturally integrating predictive world models into the core training and reasoning processes.1
This structural change means fusing sensory learning—where the model learns physics, forces, and causality via video streams and real-world simulation—with its powerful linguistic and strategic capacity.5 Until models can reliably self-generate, test, and rectify physical and abstract scenarios in a non-linguistic environment without relying on explicit, engineered planning instructions, the architectural journey to AGI remains incomplete.
VII. Conclusion: Key Takeaways and Future Trajectory
Gemini 3.0 represents a successful and decisive pivot, marking the transition from the Large Language Model (LLM) era toward the Agentic Language Model (ALM) era. Architectural features like the Deep Think mechanism and Thought Signatures have successfully solved critical reliability issues, such as reasoning drift and the inability to sustain logic over long operational horizons, that plagued previous models.
For developers and enterprise strategists, the practical takeaway is that Gemini 3.0 offers a robust, controllable, and powerful foundation for building the next generation of complex, autonomous workflows. It is undeniably the best current example of Artificial General Utility. However, we must maintain critical philosophical scrutiny: Gemini 3.0 provides a sophisticated, high-fidelity imitation of generalized intelligence, but it does not signal the full emergence of genuine, architecturally grounded AGI.
Works cited
- What does Yann LeCun think about AGI? A summary of his talk, “Mathematical Obstacles on the Way to Human-Level AI” – LessWrong, accessed November 24, 2025, https://www.lesswrong.com/posts/jKCDgjBXoTzfzeM4r/what-does-yann-lecun-think-about-agi-a-summary-of-his-talk
- Google Gemini 3.0 launched: CEO Sundar Pichai says ‘it’s the best model in the world for multimodal understanding’, accessed November 24, 2025, https://timesofindia.indiatimes.com/technology/tech-news/google-gemini-3-0-launched-ceo-sundar-pichai-says-its-the-best-model-in-the-world-for-multimodal-understanding/articleshow/125415902.cms
- Gemini 3 is available for enterprise | Google Cloud Blog, accessed November 24, 2025, https://cloud.google.com/blog/products/ai-machine-learning/gemini-3-is-available-for-enterprise
- On Missing Pieces Towards Artificial General Intelligence in Large Language Models – arXiv, accessed November 24, 2025, https://arxiv.org/pdf/2307.03762
- LeCun’s AI paradigm critique upends LLM future – AI CERTs News, accessed November 24, 2025, https://www.aicerts.ai/news/lecuns-ai-paradigm-critique-upends-llm-future/
- Gemini 3: The First AI That Thinks Before It Speaks | by Anil K Shukla, PhD – Medium, accessed November 24, 2025, https://medium.com/@shuklaks/gemini-3-the-first-ai-that-thinks-before-it-speaks-4bbad7f4a420
- What is Gemini 3 Deep Think? All You Need to Know – CometAPI – All AI Models in One API, accessed November 24, 2025, https://www.cometapi.com/what-is-gemini-3-deep-think-all-you-need-to-know/
- Building AI Agents with Google Gemini 3 and Open Source Frameworks, accessed November 24, 2025, https://developers.googleblog.com/building-ai-agents-with-google-gemini-3-and-open-source-frameworks/
- Gemini 3 Pro – Model Card – Googleapis.com, accessed November 24, 2025, https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
- Gemini 3 vs. GPT-5.1 vs. Claude 4.5: Benchmarks Reveal Google’s New AI Leads in Reasoning & Code – Vertu, accessed November 24, 2025, https://vertu.com/lifestyle/gemini-3-launch-google-strikes-back-less-than-a-week-after-gpt-5-1-release/
- Gemini 3.0 vs GPT-5.1 vs Claude Sonnet 4.5: Which one is better? – Bind AI IDE, accessed November 24, 2025, https://blog.getbind.co/2025/11/19/gemini-3-0-vs-gpt-5-1-vs-claude-sonnet-4-5-which-one-is-better/
- A new era of intelligence with Gemini 3 – Google Blog, accessed November 24, 2025, https://blog.google/products/gemini/gemini-3/
- Google Gemini 3 Benchmarks – Vellum AI, accessed November 24, 2025, https://www.vellum.ai/blog/google-gemini-3-benchmarks
- Gemini 3 vs GPT-5 vs Claude 4.5 vs Grok 4.1: The Ultimate Reasoning Performance Battle, accessed November 24, 2025, https://vertu.com/lifestyle/gemini-3-vs-gpt-5-vs-claude-4-5-vs-grok-4-1-the-ultimate-reasoning-performance-battle/
- Gemini 3.0: The Next Leap in Multimodal AI | by Jay Kim | Nov, 2025 – Medium, accessed November 24, 2025, https://medium.com/@bravekjh/gemini-3-0-the-next-leap-in-multimodal-ai-7eac34904521
- Google Antigravity — The Ultimate AI Boost for Your Developer Productivity, accessed November 24, 2025, https://morfly.medium.com/google-antigravity-the-ultimate-ai-boost-for-your-developer-productivity-afb6d624fd76
- Tutorial : Getting Started with Google Antigravity | by Romin Irani – Medium, accessed November 24, 2025, https://medium.com/google-cloud/tutorial-getting-started-with-google-antigravity-b5cc74c103c2

