
Have you ever asked an AI chatbot like ChatGPT a question, only to get an answer that’s confidently incorrect? Maybe it cited an event that never happened or gave you information that was years out of date. This frustrating experience, often called an AI “hallucination,” is one of the biggest challenges for Large Language Models (LLMs),.But what if there was a way to give these powerful AI models an open-book exam instead of a closed-book one?
That’s exactly what Retrieval-Augmented Generation (RAG) does. RAG is an AI framework that supercharges LLMs by connecting them to external, authoritative knowledge bases before they generate a response. This allows them to pull in up-to-date, specific, and factual information, making their answers dramatically more accurate and reliable.
In this post, we’ll break down in simple terms how RAG works, why it’s a game-changer for making AI more trustworthy, and how it’s already being used in the real world.
The Core Problem: Why Standard LLMs Need Help
To understand why RAG is so important, we first need to look at the built-in limitations of standard LLMs.
- The Knowledge Cutoff: LLMs are trained on a massive but static snapshot of the internet. This means they have a “knowledge cutoff” date and are completely unaware of any events, data, or information that has appeared since their training was completed,. Asking a standard LLM about last week’s news is like asking a history book to predict the future.
- The Hallucination Dilemma: When an LLM doesn’t know the answer to a question, it doesn’t just say “I don’t know.” Instead, it tries to predict the most plausible-sounding sequence of words, which can lead to it inventing facts, figures, or sources,. These “hallucinations” are a major barrier to trusting AI for critical tasks.
- The Generic Knowledge Gap: A standard LLM has no access to your company’s private or domain-specific information. It can’t answer questions about your internal HR policies, the specs of your latest product, or the details of a confidential client report.
How RETRIEVAL-AUGMENTED GENERATION (RAG) Works: A Step-by-Step Guide
RAG solves these problems with an elegant two-step process: first, it retrieves relevant information, and then it uses that information to generate an answer.
Think of it like this: Instead of asking an author to write an article from memory, you first hire a skilled researcher to find the most relevant articles, reports, and facts. The author then uses only those hand-picked documents to write their piece. The result is more accurate, specific, and verifiable.
Here’s how the RAG system does it, broken into two phases.
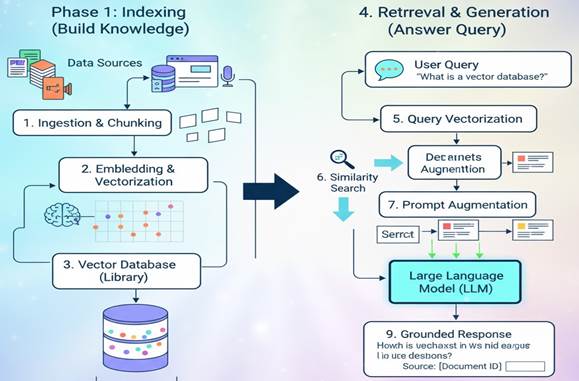
Two-Phase RAG workflow
Phase 1: Indexing (Building the Knowledge Library)
Before the AI can answer any questions, it needs a library to pull information from. This is where indexing comes in.
- Data Ingestion: First, you load your data sources. This can be anything from PDFs, Word documents, and web pages to entire databases,. For a company, this might include its internal knowledge base, product manuals, and HR documents.
- Chunking: Documents are too long for an AI to consider all at once. So, the system breaks them down into smaller, manageable “chunks” or paragraphs. This is like tearing pages out of a book to focus on the most relevant sections.
- Embedding & Vectorization: This is where the magic happens. Each chunk of text is converted into a numerical representation called a “vector embedding”. Think of this as turning the meaning and context of a sentence into a set of coordinates on a giant map. Chunks with similar meanings will have coordinates that are very close to each other.
- Vector Database: These numerical vectors are stored in a special, highly efficient database called a vector database. This database is now a searchable knowledge library that the AI can consult in milliseconds,.
Phase 2: Retrieval and Generation (Answering a Query)
Now that the library is built, the system is ready to answer a user’s question.
- User Query: A user asks a question, for example, “How much paid time off do new employees get?”
- Query Vectorization: Just like the documents, the user’s question is converted into a vector embedding. This gives the question its own set of coordinates on the “meaning map”.
- Similarity Search: The system then searches the vector database to find the text chunks whose vectors are closest to the question’s vector,. In our example, it would find chunks from the company’s HR policy documents that talk about “paid time off,” “vacation days,” and “new hires.”
- Prompt Augmentation: The original question is then combined with the relevant chunks of text retrieved from the database. The system sends this “augmented prompt” to the LLM. It essentially says: “Using only the following information [retrieved text chunks], answer this question: ‘How much paid time off do new employees get?'”
- Grounded Generation: The LLM generates a final answer based only on the context it was just given,. This ensures the response is “grounded” in the source data, not its own pre-trained (and possibly outdated) knowledge. The answer might be: “According to the employee handbook, new employees receive 15 days of paid time off per year.”
Key Benefits of Using a RAG System
Adopting a RAG framework offers several powerful advantages that make AI systems far more practical and trustworthy.
- Enhanced Accuracy and Reliability: By grounding the LLM in factual, retrieved data, RAG significantly reduces the risk of hallucinations and ensures the answers are based on reality,.
- Access to Real-Time Information: RAG overcomes the knowledge cutoff problem. As long as you keep your knowledge library updated, the AI can provide answers based on the very latest information,.
- Increased Trust and Transparency: Many RAG systems can cite their sources, showing the user exactly which document or chunk of text was used to generate the answer. This allows for human verification and builds trust in the system,.
- Cost-Effective and Scalable: Constantly retraining a massive LLM with new data is incredibly expensive and time-consuming. With RAG, you only need to update the much smaller vector database, which is far more efficient and affordable,.
- Greater Control and Data Privacy: RAG allows organizations to use their own proprietary data securely. The information is used to answer a query but is not absorbed into the LLM’s core training, which helps maintain data privacy and control,.
Real-World Applications of RAG
RAG isn’t just a theoretical concept; it’s already powering a new generation of intelligent applications across various industries.
- Smarter Customer Support: Instead of generic replies, RAG-powered chatbots can provide customers with precise answers drawn directly from product manuals, technical guides, and company knowledge bases, resolving issues faster and more accurately,.
- Efficient Internal Knowledge Management: Employees can ask questions in natural language—like “What is our travel reimbursement policy?”—and get instant, accurate answers from internal HR documents, policies, and reports, saving hours of searching,.
- Advanced Research and Analysis: Professionals in fields like law, medicine, and finance can use RAG to quickly query and summarize information from vast libraries of research papers, legal documents, or financial reports, accelerating their workflow and improving decision-making,.
The Future of RAG: Challenges and What’s Next
While RAG is a huge step forward, it’s not perfect. The quality of its answers is highly dependent on the quality of the source data, a principle known as “garbage in, garbage out”. Optimizing the retrieval process to always find the most relevant chunks is also an ongoing challenge,.
Looking ahead, the future of RAG is exciting. We’re seeing the emergence of multimodal RAG, which can retrieve information from images, audio, and videos, not just text. We’re also moving towards more autonomous, agentic RAG systems that can reason about a query, decide what information it needs, and perform multiple retrieval steps to find the best possible answer.
Conclusion: Why RAG is Essential for the Future of AI
Retrieval-Augmented Generation is more than just a clever technique; it’s a fundamental shift in how we build and interact with AI. By bridging the gap between the broad, creative power of LLMs and the specific, factual data of the real world, RAG makes AI more reliable, useful, and trustworthy.
As we rely more on AI to answer our questions and automate our work, ensuring that these systems are grounded in truth is essential. RAG is a crucial step in that direction, paving the way for more practical and powerful AI applications in every industry.

